|
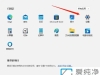
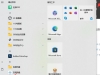
最近有用户在在Win11电脑上安装CAD软时候,安装界面提示缺少.NET组件的错误,导致无法正常安装CAD软件,这通常是由于系统中未安装或未正确安装必需的.NET Framework版本导致的。为此小编给你提供简单Win11安装cad缺少net组件解决方法,在这里根据该方法可以轻松进行操作,解决问题。 一、教程系统环境 - 操作系统:Windows 11(64位) - 电脑机型:任意支持Windows 11的机型 - 软件:CAD安装包、.NET Framework安装包 - 其他:管理员权限 二、问题描述 在安装 CAD 软件(如 AutoCAD)时,很多用户可能会遇到一个常见的错误提示:“缺少 .NET 组件”。这个问题通常是由于系统缺少某些必需的 .NET Framework 版本或相关组件所导致的。NET Framework 是许多应用程序,尤其是 CAD 软件的基础组件。解决此问题的方法通常是安装或修复这些必需的组件。 三、具体解决方法如下 方法 一:启用 Windows 功能中的 .NET Framework 1、首先鼠标右键点击win11系统任务栏中的开始菜单按钮,然后在弹出的右键菜单中选择 运行 功能。 2、在打开的运行窗口中,输入控制面板命令:【control】,回车或者点击确定打开控制面板。 3、在打开的控制面板中,找到 程序 选项下面的 卸载程序 选项点击打开。 4、在打开的界面中,鼠标点击左边菜单中 启用或关闭 Windows 功能 选项。 5、然后在打开的Windows 功能 界面中,找到.NET Framework 3.5 (包括 .NET 2.0 和3.0)功能进行勾选。 6、然后电脑就会自动搜索需要的.net文件,然后等待net组件下载安装即可。 方法二:手动下载和安装.NET框架 1. 访问.NET框架官方网站或其他可信来源,下载与您的操作系统版本兼容的.NET安装包。建议下载最新版本的.NET框架以确保兼容性和安全性。 2. 下载完成后,运行安装包并按照提示进行安装。请确保以管理员身份运行安装程序,以避免权限不足导致的问题。 3. 安装完成后,建议重启计算机以确保.NET框架的正确加载和应用。 通过上述步骤,您应该能够成功解决Win11安装CAD时提示缺少.NET组件的问题。如果遇到特殊情况或无法解决的问题,请及时联系专业技术人员或CAD软件厂商寻求帮助。
|